

Lorsque les humains disent qu’un événement est « probable » ou « probable », ils ont généralement une compréhension commune, bien que vague, de ce qu’ils veulent dire. Mais mes collègues et moi avons remarqué que les chatbots IA comme ChatGPT n’évaluent pas les probabilités de la même manière que nous le faisons lorsque nous utilisons les mêmes mots.
Nous avons récemment publié une recherche dans la revue NPJ Complexity suggérant que l’IA des modèles de langage à grande échelle, bien que performante en conversation, ne parvient souvent pas à se coordonner avec les humains lorsqu’elle communique l’incertitude. Cette étude s’est concentrée sur les mots de probabilité estimée, y compris des termes tels que « probablement », « probablement » et « presque certain ».
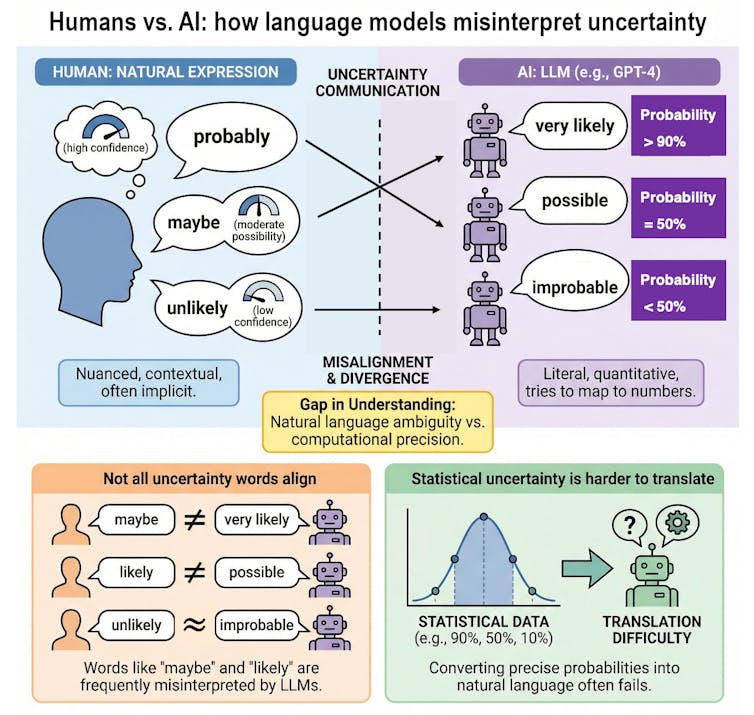
La comparaison de la façon dont le modèle d’IA et les humains mappent ces mots à des pourcentages numériques révèle un écart important entre les humains et les modèles linguistiques à grande échelle. Les modèles ont tendance à être d’accord avec les humains sur des points extrêmes tels que « impossible », mais divergent considérablement sur des mots détournés tels que « pourrait ». Par exemple, un modèle utilise le mot « probable » pour représenter une probabilité de 80 %, mais un lecteur humain suppose que cela signifie quelque chose de plus proche de 65 %.
Cela peut être dû au fait que les humains peuvent interpréter des mots comme « probable » et « probable » en fonction d’indices contextuels et de leur expérience personnelle. En revanche, un modèle linguistique étendu fait la moyenne des utilisations contradictoires de ces mots dans les données d’entraînement, ce qui peut entraîner des divergences avec les interprétations humaines.
Notre étude a également révélé que le modèle linguistique à grande échelle est sensible au langage spécifique au sexe et au langage spécifique utilisé pour les invites. Lorsque l’invite passait de « il » à « elle », les estimations de probabilité de l’IA devenaient souvent plus strictes, reflétant les biais intégrés dans les données d’entraînement. Les estimations de probabilité de l’IA changeaient souvent lorsque l’invite passait de l’anglais au chinois. Cela est probablement dû aux différences entre l’anglais et le chinois dans la façon dont les gens expriment et comprennent l’incertitude.
pourquoi est-ce important
Loin d’être une bizarrerie linguistique, cette inadéquation constitue un défi fondamental pour la sécurité de l’IA et l’interaction homme-IA. Alors que les modèles linguistiques à grande échelle sont de plus en plus utilisés dans des domaines à enjeux élevés tels que la médecine, les politiques gouvernementales et les rapports scientifiques, la manière dont les risques sont communiqués est devenue une question de confiance du public.
Par exemple, si un assistant IA assistant un médecin décrit un effet secondaire comme « improbable », mais que les calculs internes du modèle indiquent que « improbable » est beaucoup plus élevé que l’interprétation du médecin, la décision qui en résulte peut être erronée.
Quelles autres recherches sont en cours ?
Les scientifiques étudient la manière dont les humains quantifient l’incertitude depuis les années 1960, un domaine mis au point par les analystes de la CIA pour améliorer les rapports de renseignement. Récemment, il y a eu une explosion de littérature sur les modèles de langage à grande échelle qui examinent les réseaux de neurones pour mieux comprendre leur « comportement » et leurs modèles de langage.
Nos recherches ajoutent encore à la complexité en traitant l’interaction entre les humains et l’intelligence artificielle comme un système biologique dont le sens peut être dégradé. Plutôt que de simplement mesurer si une IA est « intelligente », nous nous demandons si elle est optimisée.
D’autres chercheurs étudient actuellement si ces erreurs peuvent être corrigées par des invites dites de chaîne de pensée, ou en demandant à l’IA de démontrer son comportement. Cependant, nos recherches montrent que même l’inférence avancée ne peut pas toujours combler le fossé entre les données statistiques et les étiquettes verbales.
quelle est la prochaine étape
L’objectif du développement futur de l’IA est de créer des modèles qui non seulement prédisent le prochain mot probable, mais qui comprennent réellement le poids de l’incertitude que véhiculent les mots. Les chercheurs souhaitent une mesure de cohérence plus robuste pour garantir que le modèle sélectionne le même mot chaque fois qu’il détecte une chance de 10 % dans les données.
Alors que nous évoluons dans un monde où l’IA résume les articles scientifiques et gère les emplois du temps des gens, s’assurer que « peut-être » signifie « probablement » est une étape cruciale pour faire de ces systèmes des partenaires de confiance plutôt que de simples perroquets sophistiqués.
Les notes de recherche sont de courts résumés de recherches universitaires intéressantes.
Mayank Kejriwal, professeur adjoint d’ingénierie des systèmes industriels, Université de Californie du Sud
Cet article est republié à partir de The Conversation sous une licence Creative Commons. Lisez l’article original.
![]()